在我们实际工作中,提到分布式数据采集框架,就不免说起数据去重的问题,对于一个7*24小时不间断的爬虫框架来说,爬虫任务循环往复调度,就必须将数据去重做好,否则就会对同一数据或相似数据进行多次抓取,造成系统资源的浪费,且可能给用户推送N条相同或相似的资讯,致使用户体验感差等问题。本文主要介绍大数据文本去重的方法实现及流程,本人水平有限,如贴中哪里有问题,欢迎批评指正。
资讯抓取的采集系统中,大数据文本去重的过程大致如下:
- 1.
redis对抓取资讯的链接进行过滤性去重 - 2.
simhash去重
redis对链接URL过滤性去重
上面我们提到,分布式数据采集框架一般都是7*24小时不间断抓取的,我们只需要对任务进行抓取配置,例如:任务名称、任务描述、任务优先级、是否重复抓取、抓取间隔、下载路由、重抓次数等,然后上传站点初始url文件及配置等文件,框架就会自动调度、分发任务
- 那么,问题来了。假设站点
A有一篇资讯-分布式及数据同步链接为https://www.bscsjsn.com/archives/distributed.html(此处用博主自己的链接),我们对该站点A进行初始配置的时候,抓取间隔设置为1小时抓取一次,但实际抓取过程中,发现该站点内的资讯更新时快时慢,1小时后,这篇资讯还在资讯列表页,甚至再过1小时也还在,那么爬虫每隔1小时都会把这篇资讯抓取进我们的系统中 - 这个时候,就需要借助
redis的Hash类型来帮我们做过滤性去重,假设我们给定站点A一个统一的job_id为108,那么我们在抓取列表页时,需要多加一个步骤; - 将字符串
job_和站点A任务的真实job_id进行拼接,得到如下字符串job_108; - 每次解析到新的详情页链接,需要放到调度队列中重新调度之前,我们先进行判断,判断
redis中Hash为job_108的数据中是否已经存在当前链接url,不存在则抓取,并把当前url链接存入到job_108中;如果存在,则说明该url链接已经抓取过了,则丢弃,整个流程就会变成下图:
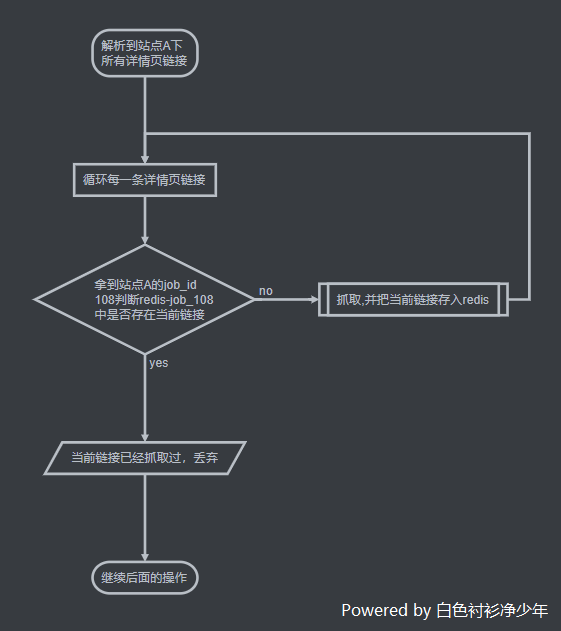
- 这样,我们只需要控制好
redis中job_108key的失效时间,就能解决上述这种同一数据源重复抓取的问题,大大提升了采集系统的资源利用率
simhash去重
反应比较快的同学其实已经发现了,上述的解决方法有bug存在,如果站点
A和站点B分别抓取了站点C的一篇资讯分布式及数据同步,将其url链接变成自己独有的:
- 站点
A-分布式及数据同步-url:https://guaini.blog/archives/distributed.html(举例说明,并不真实存在,域名为博主好友拥有,已得到授权) - 站点
B-分布式及数据同步-url:https://www.whusan.com/archives/distributed.html(举例说明,并不真实存在,域名为博主好友拥有,已得到授权)
这种情况,其实资讯还是一样的资讯,也还是会被爬虫抓取进我们的系统,这个时候,就需要我们今天的主角-
simhash来处理了
simhash介绍
simhash是google用来处理海量文本去重的算法。 google出品,你懂的。 simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似
simhash与hash算法的区别
传统Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统hash算法产生的两个签名,如果不相等,除了说明原始内容不相等以外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大,所以传统Hash是无法在签名的维度上来衡量原内容的相似度。而SimHash本身属于一种局部敏感哈希算法,它降维生成的hash签名在一定程度上可以表征原内容的相似度。
算法实现过程大致如下:
- 对文本分词,得到N维特征向量(默认为64维)
- 为分词设置权重(tf-idf)
- 为特征向量计算哈希
- 对所有特征向量加权,累加(目前仅进行非加权累加)
- 对累加结果,大于零置一,小于零置零
- 得到文本指纹(fingerprint)
具体的流程实现
simhash的算法具体分为5个步骤:分词、hash、加权、合并、降维,具体过程如下:
- 分词
- 给定一段语句或者一段文本,进行分词,得到有效的特征向量,然后为每一个特征向量设置一个5个级别(1—5)权值。例如给定一段语句:“和世界交手这么多年,你是否兴致盎然、风采依旧”,分词后结果为:
世界交手兴致盎然风采依旧,然后为每个特征向量赋予权值:世界(5)交手(4)兴致(2)盎然(3)风采(2)依旧(1),其中括号里的数字代表这个单词在整条语句中的重要程度,数字越大代表越重要
- 给定一段语句或者一段文本,进行分词,得到有效的特征向量,然后为每一个特征向量设置一个5个级别(1—5)权值。例如给定一段语句:“和世界交手这么多年,你是否兴致盎然、风采依旧”,分词后结果为:
- hash
- 通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如
世界的hash值Hash(世界)为110101,交手的hash值Hash(交手)为101001。就这样,字符串就变成了一系列数字
- 通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如
- 加权
- 在hash值的基础上,给所有特征向量进行加权,即W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给
世界的hash值110101加权得到:W(世界) = 110101 5 = 5 5 -5 5 -5 5,给交手的hash值101001加权得到:W(交手)=101001 4 = 4 -4 4 -4 -4 4,其余特征向量类似此般操作
- 在hash值的基础上,给所有特征向量进行加权,即W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给
- 合并
- 将上述各个特征向量的加权结果累加,变成一个序列串。拿前两个特征向量举例,例如
世界的5 5 -5 5 -5 5和交手的4 -4 4 -4 -4 4进行累加,得到5+4 5-4 -5+4 5-4 -5-4 5+4,得到9 1 -1 1 -9 9
- 将上述各个特征向量的加权结果累加,变成一个序列串。拿前两个特征向量举例,例如
- 降维
- 对于n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的
9 1 -1 1 -9 9降维(某位大于0记为1,小于0记为0),得到的01串为:1 1 0 1 0 1,从而形成它们的simhash签名
- 对于n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的
相似度比较,计算出两篇资讯的simhash值,那如何计算两个simhash的相似度呢?这里就引入了海明距离的概念,
海明距离是判断文本相似度的众多标准之一,类似的还有欧氏距离、余弦夹角等,有兴趣的同学可以再深度研究,话说回来,两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下:10101和00110从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)由simhash算法,我们就可以处理掉不同数据源中相似资讯的去重工作
留一个问题思考,那么在我们实际工作中的应用场景下,采集程序不间断的抓取,如何高效做到当前抓取的资讯信息与已经入数据库的海量资讯是否相似?这个问题下篇分解


暂无评论