自站长从业的第一天起,身边的大神就告诉站长,做大数据,必须要记住并深刻理解的一个词就是
分布式。工作至今,也没有写过一篇关于分布式概念的帖子,本文主要介绍分布式及分布式系统中数据同步的各种主流存储服务的具体实现过程,这里尽量用大白话做个简单的总结,帮助理解,本人水平有限,如贴中哪里有问题,欢迎批评指正。
百度百科
分布式计算是计算机科学中一个研究方向,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给多个计算机进行处理,最后把这些计算结果综合起来得到最终的结果。分布式网络存储技术是将数据分散地存储于多台独立的机器设备上。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,不但解决了传统集中式存储系统中单存储服务器的瓶颈问题,还提高了系统的可靠性、可用性和扩展性。
大白话解释
其实细想想,分布式的性质抽象出来也是沿用了分治法的理念,就分布式计算来讲,一个特别大计算量的数据计算任务,如果用一台计算机来计算,假定需要1day,那么此时将该任务切分为若干个小任务,分发给N台计算机来计算,最后再将N个计算结果收集做最终计算,所用的时间就会小于1day,效率就会大大提升。
分布式系统
就存储而言,分布式是为了解决单机的容量问题,但也引入了一个新的问题,那就是数据同步的问题。关于数据同步后面我们在剖析,这里先主要说分布式。分布式系统,通过数据冗余,来保证数据的安全,以防磁盘坏死、机器宕机或者误操作造成不可逆的数据丢失情况。那么,问题来了:一个是单一数据源,担心数据丢失;另一个是不必担心数据丢失,甚至可以说数据冗余,但需要考虑数据同步一致性的问题,两种方案选那种?答案是肯定的,两者相害 取其轻呗,先保证了数据不会丢失的情况下,在考虑数据同步的问题。
前言
要想写一个分布式系统,首先需要解决的问题就是数据同步。同步,这两个字,难住了多少人。
是同步,还是异步?是push,还是pull?谁是master,谁是slave?中心化,还是对等节点?这些问题,都把分布式系统的设计者将要面对的问题上升了一个层级。
那么,我们看看市面上主流的几个存储服务,是如何设计应对数据同步问题的。
不同存储服务选用不同的主从同步方案
为什么要做主从同步?上面已经说了一点,为了数据的安全性;另外还有一点是主从架构可以实现读写分离,为系统提供更快的响应速度,保证系统高可用。
Mysql
实现原理
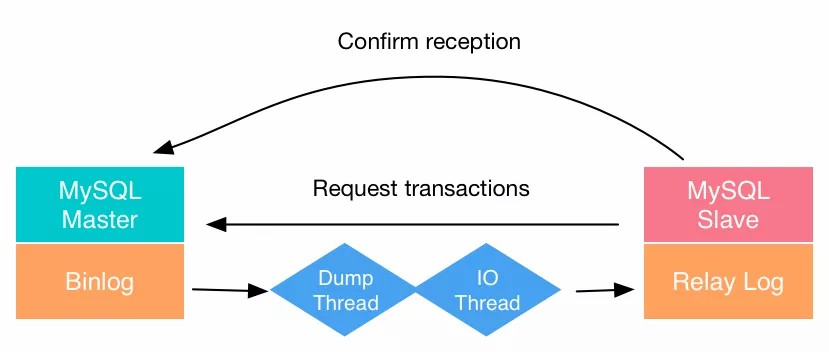
- Mysql的主服务器叫做
master,从服务器叫做slave。- 在master机器上的操作
- 当master上的数据发生变化时,该事件变化会按照顺序写入
bin-log中。当slave连接到master的时候,master机器会为slave开启binlog dump线程。当master的binlog发生变化的时候,bin-log dump线程会通知slave,并将相应的binlog内容发送给slave - 在slave机器上的操作
- 当主从同步开启的时候,slave上会创建两个线程:I/O线程,该线程连接到master机器,master机器上的binlog dump 线程会将binlog的内容发送给该I/O线程。该I/O线程接收到binlog内容后,再将内容写入到本地的
relay log(中继日志);sql线程,该线程读取到I/O线程写入的ralay log,并且根据relay log 的内容对slave数据库做相应的操作(重放)
主从同步的粒度、原理和形式
- binlog的格式分为
statement、row、mixed三种statement将变更的sql语句写入到binlog中,在准确性方面会有一定影响row将每一条记录的变化,写入到binlog中mixed上面两种的结合。Mysql会判断什么时候有用statement,什么时候用row
主从同步的延迟问题、原因及解决方案
- 由于是异步线程去拷贝,slave很容易会出现延迟。当master不幸宕机,将会造成延迟的数据丢失
- 为了解决异步复制的问题,5.5版本之后,MySQL引入了
半同步复制(semi sync)的概念。半同步处于异步和全量同步之间,master执行完事务之后,并不直接返回,而是要等待至少一个slave写入成功才返回。由于需要与至少一个slave进行交互,性能相比较异步复制肯定是有不少折损的 全复制模式当然是要等待所有的slave节点复制完成,这种安全性最高,但是效率也最低。从概念上来讲,只有一个slave的半复制就是全复制- 5.7之后,mysql实现了
组复制(group replication)协议。它支持单主模式和多主模式,但在同一个group内,不允许同时存在。听起还好像很神奇,其实它还是通过paxos协议去实现的
Kafka
实现原理
- 因为kafka是一个消息队列,所以不需要考虑随机删除和随机更新的问题,只需要关注写入问题即可。从结构上来说,kafka的同步单元是非常分散的:kafka有多个
topic,每个topic又分为多个partition,副本就是基于partiton去做的
kafka的ISR(In Sync Replica)机制
- kafka的
ISR机制被称为不丢消息机制。在说ISR机制前,先得讲一下kafka的副本(replica)的概念来加深理解
kafka的Replica
- kafka的topic可以设置有N个
副本(replica),副本数最好要小于broker的数量,也就是要保证一个broker上的replica最多有一个,所以可以用broker id指定Partition replica - 创建副本的单位是
topic的分区,每个分区有1个leader和0到N个follower,我们把N个replica分为Lerder replica和follower replica - 当producer在向
partition中写数据时,根据ack机制,默认ack=1,只会向leader中写入数据,然后leader中的数据会复制到其他的replica中,follower会周期性的从leader中pull数据,但是对于数据的读写操作都在leader replica中,follower副本只是当leader副本挂了后才重新选取leader,follower并不向外提供服务
kafka的"同步"
- kafka不是完全同步,也不是完全异步,而是上面提到的
ISR机制 - leader会维护一个与其基本保持同步的Replica列表,该列表称为
ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护 - 如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除
-
当ISR中所有Replica都向Leader发送ACK时,leader才commit
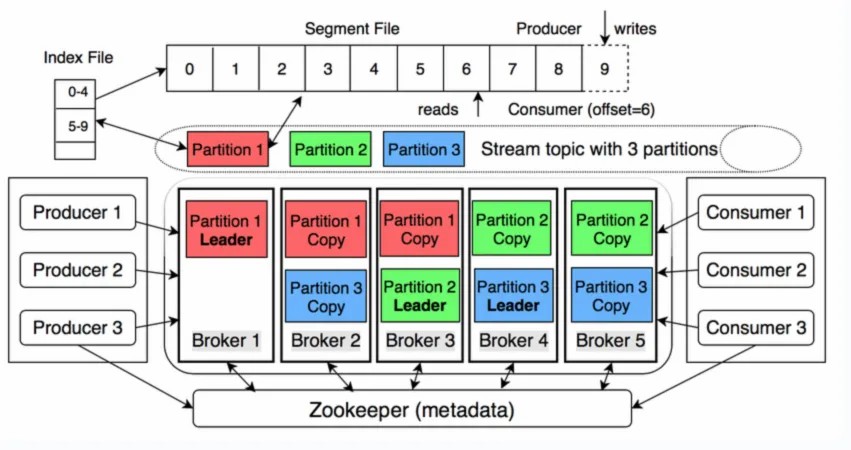
从上图我们可以看出,kafka的节点是通过与zookeeper心跳机制来检查每个节点的连接
kafka的Ack
那如何才算是消息发送成功?还得看Ack的发送级别
0表示异步发送,消息发送完毕就算是成功了1leader主副本写入完成,就算是发送成功了-1leader发送完成,并且ISR中的副本都需要回复ack
0和1的情况下,kafka都有丢失消息的可能。在-1的情况下,也需要保证至少有一个follower commit成功才能保证消息安全。如果follower都不能追赶上leader,则会被移除出 ISR列表。没错,是直接移除。当ISR为空,则kafka的分区和单机是没有区别的,所以kafka提供了min.insync.replicas参数规定了最小ISR
Redis
redis的主从复制原理
- redis是内存键值对(key-value)型数据库,在速度上远超其他数据库,理论上主从同步应该较容易,但redis的应用场景一般被作在缓存层,在高流量/高QPS的极端情况下,主从复制依赖会发生问题
- redis的
slave连接上之后,首先会进行一次全量同步。它会发送psync命令到master,然后master执行bgsave生成一个rdb文件。全量同步就是复制这个rdb快照文件到slave - 那么,问题来了,在全量复制的过程中,产生的数据怎么办?肯定是要缓存起来的,
master会开启一个buffer,然后记录全量复制过程中产生的新数据,在全量同步完成之后再补齐增量数据 slave断线之后也不需要每次都执行全量同步,为了配合增量,还引入了复制偏移量(offset)、复制积压缓冲区(replication backlog buffer)和运行ID(run_id)三个概念。可以看出它们都是为了标识slave,以及它的复制位置和缓冲区用的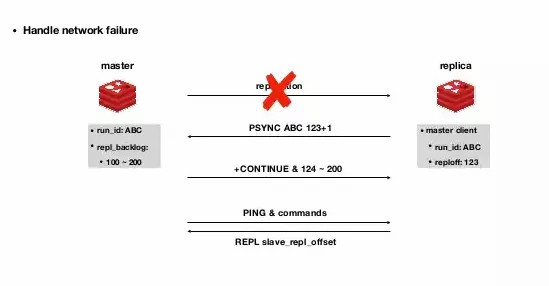
- 之后的同步,就可以一直使用psync去复制,依然是异步复制
- redis的主从复制一致性主要依赖内存来实现,级别必然是很弱的,但内存的速度快是磁盘复制所不能及的,快能解决很多问题
ElasticSearch
es的主从复制原理
es是基于lucene的搜索引擎,数据节点会包含多个索引(index),每个索引包含多个分片(shard),每个分片又包含多个副本(replica)- 从概念上来说的话,es与kafka是有些相似之处的,es的复制单元是分片
- es的数据依然是先写
master,它同样维护了一个同步中的slave列表(InSyncAllocationIds),处于yellow和red状态的副本当然是不在这个列表中的 master需要等待所有这些正常的副本写入完成后,才返回给客户端,所以一致性级别是比较高的,因为它的slave节点是要参与读操作的,可以说,es几乎是一个近实时系统- 由于它是一个数据库,所以依然会有删除和更新操作,
Translog相当于wal日志,保证了断电的数据安全,这和其他rdbms的套路是一致的
MongoDB
mongodb主从、副本、分片
- mongodb提供了三种部署方式:
主从复制(Master-Slaver),主从副本的模式,现在已经不推荐使用了副本集(Replica Set), 取代了Master-Slaver 模式,是一种互为主从的关系,Replica Set 将数据复制多份保存,不同服务器保存同一份数据,在出现故障时自动切换,实现故障转移,在实际生产中非常使用分片(Sharding),适合处理大量数据,将数据分开存储,不同的数据保存到不同的服务器中
- Sharding 模式追求的时高性能,而且是三种集群种最复杂的,再实际生产种,通常将Replica Set 和Sharding两种技术结合使用
mongodb同步原理
Initial Sync全量同步Replication即sync oplog- 全量同步开始,获取同步源上的最新时间戳t1
- 全量同步集合数据,建立索引(比较耗时)
- 获取同步源上最新的时间戳t2
- 重放t1到t2之间所有的oplog
- 全量同步结束
- 全量同步结束后,Secondary就开始从结束时间点建立tailable cursor,不断的从同步源拉取oplog并重放应用到自身,这个过程并不是由一个线程来完成的,mongodb为了提升同步效率,将拉取oplog以及重放oplog分到了不同的线程来执行
- mongodb采用bully选举算法,主节点的变更,会存放在特定的系统表中。slave会定时拉取这些变更,并应用。从这种描述中也可以看出,mongodb在同步延迟或者单节点出问题的时候,会有丢失数据的可能
Cassandra
cassandra集群模式同步
- cassandra是一个非常有名的CAP理论实践数据库,更多的像一个AP数据库,目前在db-engines.com依然有较高的排名
- 数据存储是表的概念,一个表可以存储在多台机器上。它的分区,是通过partition key来设计的,数据分布非常依赖于hash函数。如果某个节点出现问题怎么办?那就需要一致性hash的支持
- cassandra非常有意思,它的复制(replicas)并不像其他的主备数据一样,它更像是多份master数据,这些数据都是同时向外提供服务的。当掉一个检点,并不需要主备切换
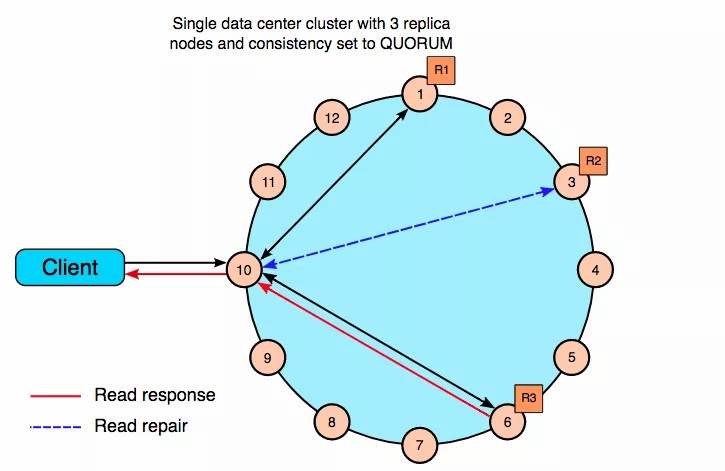
- 为什么可以做到这种程度呢?因为cassandra追求的是最终一致性。分布式系统由于副本的存在,不可避免的要异步或者同步复制。那到底复制到什么程度才算是合适的呢?
Quorum的R+W就是一个权衡策略quorum = (sum_of_replication_factors / 2) + 1 - 什么意思呢?考虑到你有5个抽屉,然后随机放入W个球,求需要多少次R,才能拿出一个球。假如你向里面放了1个球,你需要打开5次,才能每次都有正确的判断,此时R=5、W=1;当你放了2个球,则你只需要打开4次就可以了;假如你放入了5个球,那就只需要读一次
- 当R+W>N的时候,属于强一致性;当R+W<=N的时候,属于最终一致性
- 有意思的是,cassandra中的集群信息,即meta信息,使用gossip(push-pull-gossip)进行传递
总结
数据同步要关注一致性,故障恢复以及时效性
主要有两种数据需要同步
- 元数据信息
- 真正的数据
对于元数据信息,目前比较主流的做法,可以参考使用raft协议进行数据分发。到了真正的数据同步方面,raft协议的效率还是有些低的,所以会普遍采用异步复制的方式
在这种情况下,异步复制列表,就成了关键的元数据信息,集群需要维护这些节点的状态。最坏的情况下,异步复制节点全部不可用,master会自己运行在非常不可信的环境下
为了增加数据分配的灵活性,这些复制单元多会针对于sharding分片进行操作,由此带来的,就是meta信息的爆炸
分布式系统这么多,但并没有一个能够统一的模式。有意思的是,即使是最低效的分布式系统,也有大批的追随者。不信?看看BTC的走势就知道了


2021-10-09 17:41:10 回复
大佬牛逼
2021-10-09 17:38:48 回复
大数据同步这块讲的确实不错