从上篇文末我们得知,两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离,知道这点,那么就好办了
海量数据中,高效判断当前文本是否存在相似文本的大致流程:
-
- 建一张专门用于存放新闻simhash值的表
-
- sql判断
具体实现过程
- 上面提到了,两个simhash值的相似度判断,其实就是看两个码字的对应比特取值不同的比特数
- 讲到这里,有的同学就想到了,这不就是异或操作么?对的,我们就是要用异或去做判断
- 首先,我们新建一张Mysql表,表中添加如下字段
| 字段名 | 类型 | 释义 |
|---|---|---|
| id | int | 自增id |
| news_title_md5 | verchar | 标题MD5值 |
| news_title_simhash | bigint | 标题simhash值 |
| news_simhash | bigint | 正文simhash值 |
| news_time | datetime | 新闻时间 |
| strategy | varchar | 去重应用策略 |
| news_length | int | 新闻正文长度(为了过滤长度不到30个字符的新闻,因simhash算法对短文本的误判率极高) |
| is_deleted | int | 是否删除标识 |
- 计算当前新闻标题的MD5值,simhash值,正文的simhash值
- 先判断当前新闻标题MD5是否存在于上表,存在将两篇新闻强制合并、不存在执行下一步
- 执行
sqlselect id, bit_count(#{simhash}^news_simhash) as bit_count, news_time, news_length, news_title_simhash, news_title_md5, from tableName where bit_count(#{simhash}^news_simhash)<=#{bitsDiff} order by bit_count,{simhash}为当前新闻的正文simhash值,{bitsDiff}为海明距离,经验值,给6 - 上述
sql的意思为:拿当前新闻的simhash值和表中news_simhash列的所有值做按位或操作,然后bit_count函数将按位或的结果转为二进制后计算有多少个1,也就是计算海明距离的过程,列出海明距离小于6的记录 - 如果执行
sql,返回结果为null,则证明没有与当前新闻相似的文本,将当前新闻的各项值存入表中;若返回结果不为null,说明已经存在相似文章,后续的工作是需要合并还是直接丢弃就由在座的各位决定了
思考
按照这个思路,我们整个的排重流程就会变为如下:
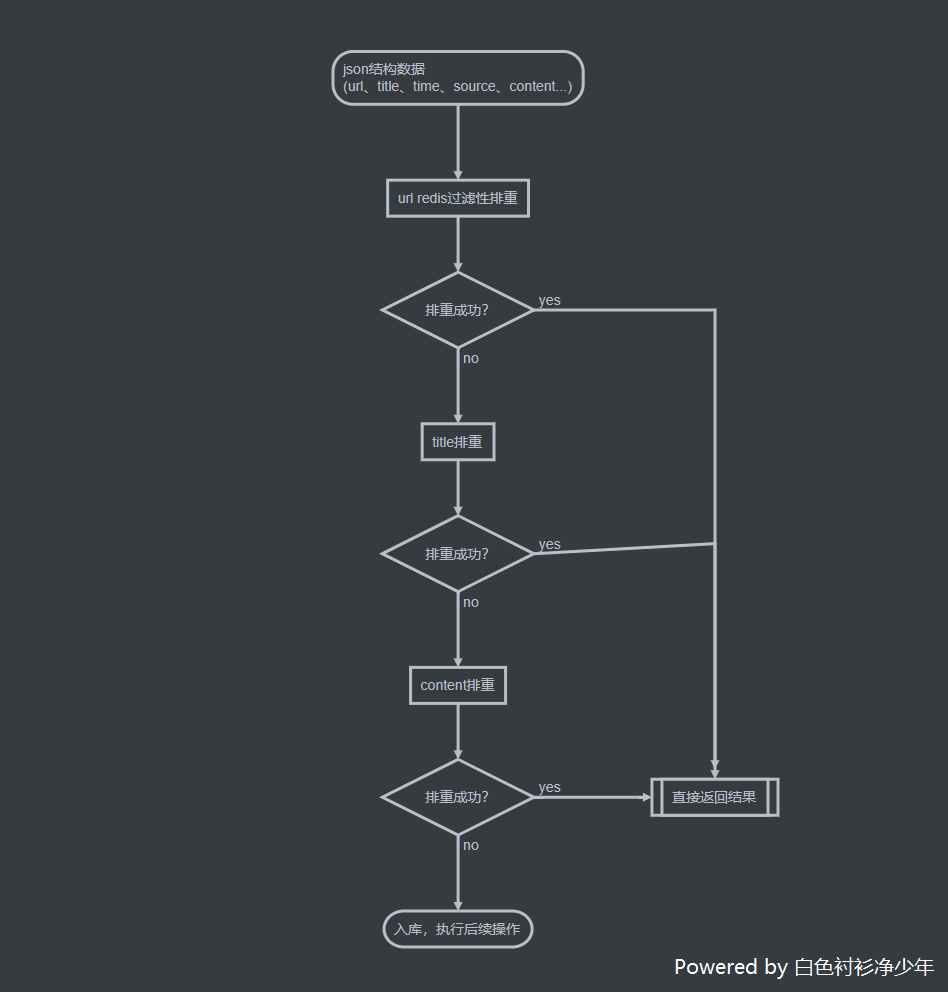
这样一层一层过滤,最终到
simhash判断的时候,其实我们的数据量并不大,再从数据库下手,定期更新去重表中的数据,给表加上相对应的索引来提高查询速度,这样就能在我们的工作中,高效的完成去重流程


2021-11-01 17:30:35 回复